
Although it’s still early to discuss the open data revolution in Estonia, opportunities to make use of public data exist. In fact, technical capabilities and political will are all in favor of open data advancements. Now, we’re at the stage where we have to take this issue – open data advancement – as part of forward-looking development strategies. But first – understanding.
A lesson in the history of open data
A short walk through the history of open data adjacent to some vital examples should help us better understand what’s at hand.
If we leave out the “internet part”, the history of open data can be traced way back in history. In 1942, a founding father of modern sociology, Rober K. Merton put down a list of criteria necessary for the sustainable development of modern science. One of the criteria was the free use of data. 15 years later, during the International Geophysical Year, 1957-1958, a notable leap in joint scientific efforts was made. Prompted by frustrations of missing adequate descriptions of certain phenomena, scientists around the world agreed to openly share scientific data with each other. Why you may wonder? Well, it meant that scientists would fill in the blanks and thrive thanks to the work of others. Arriving at conclusions, therefore, was much faster.
Recently, in 2007 – a year widely considered the beginning of the open data era – 30 thought leaders and internet enthusiasts met in Sebastopol, a small town north of San Francisco, California. The meeting resulted in a document that defined what is now known as the concept of public data. At the time, the document was made with the purpose of aiding US officials in adopting public data and means of its regulation. But – and the time would prove it – this event marked the beginning of open data evolution that would later profit everyone – individuals, organizations, and even governments themselves.
Just shortly after, in 2009, former US president, Barack Obama, adopted a memorandum on transparency and open governance (Open Government Initiative) on his first day in office. He confirmed the action with a statement that “openness strengthens our democracy and promotes the efficiency and effectiveness of government.” But not just that, the private sector would be able to use this data and drive growth alongside the government.
Fast forward to today, the open data initiative is set side by side with other so-called “open-source” movements – open license, open education, and open access. On occasions, even to the Big Data. However, the two sit far away from one another. They are different in size, and nature and serve different purposes.
Big Data vs Open Data: what’s the difference?
Much is said today about big data. But how is it different to open data?
Well, big data is defined by its size, whereas open data is determined by its purpose of use. Also, big data need not be publicly available. Picture sales history log files, cookie data, or even academic class attendance – only the organization that owns the data can yield it. As a rule of thumb, big data is raw and unprocessed. Just like oil or gas, it still has to be worked on in order to be useful.
On the other hand, the open data is not massive in size, but open, available, and free of charge. While big data serves its owners only, public data should have a big impact on creating value for people. E.g. sharing real-time doctor availability over the internet, creating the internet of things, smart cities, and so forth.
And where is the overlap between the two types of data? Well, part of big data gets converted into open data with a means of technology. Without one, there’s no other.
Thanks to both, governments are on the brink of massively improving transparency. What’s more, the use of first-rate data in analysis, predictions, or socio-economical studies carries a profound impact on the quality of decision-making and evidence-based management. Not just inside a single country.
How does Open Government come into the picture here? Well, anyone who uses this data should respect the constituents of this act: transparency, public service improvement, innovation, and efficiency. Without the constituents, both big data and open data are serving different purposes – and it’s not a good one.
What is the nature of open data?
Providing and using open data is a delicate matter. It is why it’s important to talk about the nature of data and the principles that arise from it. Here are a couple of conditions that should be taken into account:
- Open data is not real-time data. Therefore it’s not primary data but processed secondary data.
- Open data is free of personal data. I.e. the data is anonymized and shared with respect to laws and regulations.
- Open data comes with licenses and manuals. E.g. you should mention the source, comply with listed criteria, verify if the results of data processing are eligible for profits, etc.
- Open data interpretation requires basic IT knowledge. Data can be structured and delivered using different formats. In order to further process this data perception and understanding of data should not be dependent on that format.
In terms of nature, data is the same inside and outside the borders. However, not every country is in the same phase when it comes to open data advancements. It’s only fair to ask then…
Open data in Estonia: Where are we?
Estonia is in fact riding on waves of open data. If you wonder how, I suggest you examine the results of the last consensus from 2021. You shouldn’t find it hard to read the data disclosed there – it is nicely visualized and triggers a number of interesting thoughts that could lead to insights.
Here, an example of a describing the composition of the household by age group. A very telling figure commercial and service companies could use to design perfectly targeted offerings to households.
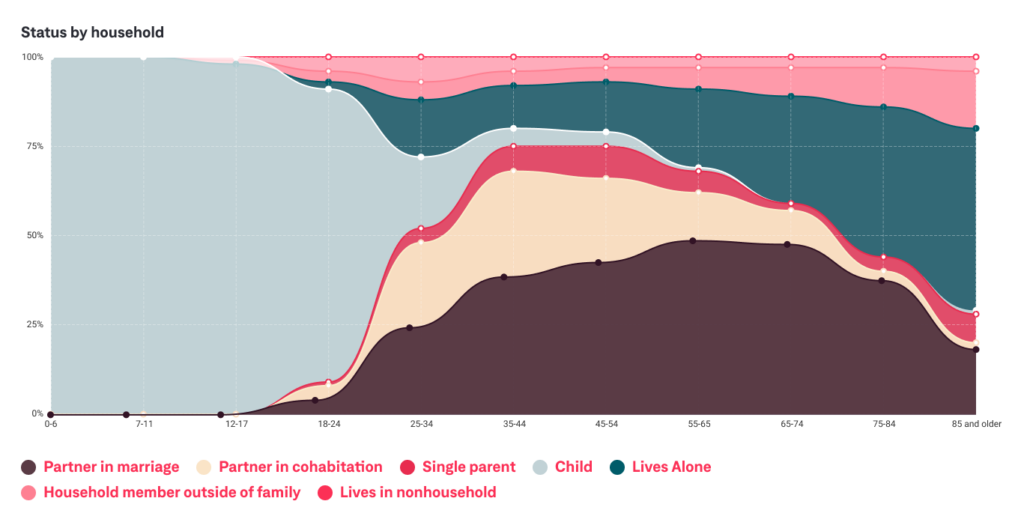
As you may have guessed, a previewed example was fairly easy to interpret. The data is not overly complex and a graph is nothing short of nicely visualized. However, open data comes in many “unfriendly” forms. In most cases, it is not easy to understand the metrics without a professional or any previous know-how.
Can anyone interpret the open data?
Data scientists, analysts, or in fact anyone who can make sense of data arrays, can draw conclusions from the data at hand.
To answer the question: No, not everyone can interpret the data. However, you can become a ” home-brewed scientist” yourself. First, you need to learn the basics of evidence-based analysis models. If you’re wondering about the level of difficulty, well… it’s not exactly as easy as basketball, but it also shouldn’t take you longer than “one or two semesters of time” considering your work and family obligations.
Second, after you slide down the learning curve, it’s crucial to try it out! To enroll in one analysis project. If you fail, you can engage in the next one with a little more experience. Ultimately, once you’re able to draw decisions from data, you will understand the power of making better-informed decisions.
Truth be told, there is no escape from the emerging world of data. Whether you’re a government official or a businessman, the data means to stay and keep on changing economies. It needs to be used now, at this moment. Whether it’s you or someone else, the results from the evidence-based analysis are promising.
If you have any further interest, please contact me: pr*********@******up.com
Additional sources:
Similar insights

Stop buying projects. Start building digital capabilities.
16/06/2026
The hidden cost of “small changes” in digital projects
09/06/2026
Minimum Viable Data: The standard all digital systems need
19/05/2026
AI is a great cost-saver – Until it’s not!
13/05/2026
Data Readiness: The foundation every digital system needs
21/04/2026
Are your people ready for transformation? A self-evaluation checklist
15/04/2026
Who Owns What in Change Management for Digital Transformation
18/03/2026
“Why Do We Pay for Analysis?” an Answer for Skeptical Executives
11/03/2026
Inside Europe’s Cybersecurity Skill Shortage in 2026
17/02/2026
Let the success
journey begin
Our goal is to help take your organization to new heights of success through innovative digital solutions. Let us work together to turn your dreams into reality.